近日,中国科学院合肥物质院智能所运动健康团队丁增辉研究员联合芝加哥大学团队,在国际上提出一种零样本视频理解动态令牌合并框架DYTO(Dynamic Token Merging framework for zero-shot video understanding),首次在视频理解中系统引入了类脑式的动态选择与压缩机制,为解决“效率-语义”权衡问题提供了新路径,为智慧医疗、在线视频分析、人机交互等应用场景的高效AI落地奠定了技术基础。该成果入选国际计算机视觉顶级会议ICCV 2025。
近年来,多模态大模型(MLLMs)极大推动了视频理解的发展,但高效、精准的零样本视频理解仍面临挑战。传统方法依赖大量标注数据和计算资源进行微调,而现有免训练方法虽效率高,却在复杂视频中难以兼顾语义完整性与上下文连贯性。如何在计算效率与语义丰富性之间取得智能平衡,成为该领域的关键难题。
DYTO框架借鉴人脑处理视觉信息的核心机制,提出一种完全无需训练的动态令牌合并方法。其突破在于通过“分层注意力选择”与“自适应信息压缩”两大策略,在计算效率与语义理解之间实现高效平衡。DYTO可无缝接入现有图像MLLMs,显著提升零样本视频理解性能,并具备进一步强化已微调模型的潜力。该框架的技术创新主要体现在以下三个方面:首先,DYTO模拟人脑的对运动、高对比的信息的“选择性注意力机制”,通过分层聚类分析视频帧的语义表示(CLS令牌),自动识别并聚焦于关键事件片段,避免对冗余信息的均匀处理,实现高效的事件感知与时间结构建模。其次,受大脑信息压缩与抽象记忆机制的启发,DYTO采用动态二分图令牌合并策略,依据每帧内容自适配地合并语义相近的视觉令牌,在减少计算负担的同时,最大程度保留语义完整性,避免信息丢失与语义失真。最后,通过模仿大脑从局部到整体的认知过程,DYTO将分层聚类与令牌合并相结合,实现从帧级视觉特征到事件级语义结构的递进式理解,增强对长视频复杂内容的整体把握能力。
实验结果证实DYTO全面刷新SOTA基准。在视频问答任务的NExTQA、EgoSchema、MVBench等多个权威基准上,DYTO的表现全面超越了所有免训练方法,甚至应用在图像模型上也会优于许多经过视频微调的模型。
博士研究生张一鸣为论文第一作者,丁增辉研究员为通讯作者。该研究获国家重点研发计划等项目支持。
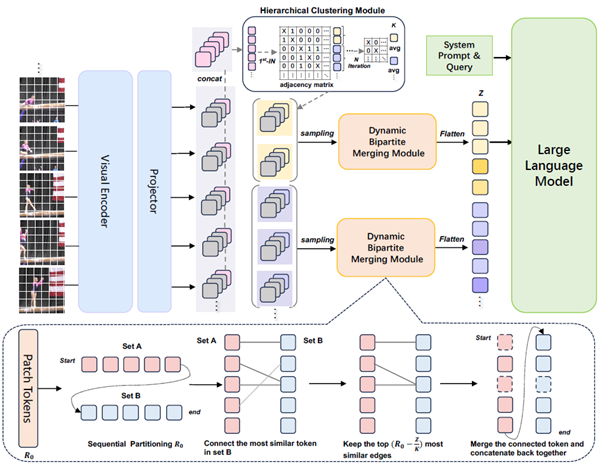
图1:DYTO 技术框架的模型




